python语法(下)
Python3 推导式 列表推导式 列表推导式格式为:
1 2 3 4 5 6 7 [表达式 for 变量 in 列表]
例题:
1 2 3 4 >>> names = ['Bob' ,'Tom' ,'alice' ,'Jerry' ,'Wendy' ,'Smith' ]>>> new_names = [name.upper()for name in names if len (name)>3 ]>>> print (new_names)'ALICE' , 'JERRY' , 'WENDY' , 'SMITH' ]
实现了:==遍历旧列表,判断,操作,生成新列表==
字典推导式 字典推导基本格式:
1 2 3 4 5 { key_expr: value_expr for value in collection }
例题:
1 2 3 >>> dic = {x: x**2 for x in (2 , 4 , 6 )} >>> dic2 : 4 , 4 : 16 , 6 : 36 }
集合推导式 同理(与字典推导式),最前面为示例(expression)
元组推导式(生成器表达式) 只不过,元组推导式返回的结果是一个生成器对象
1 2 3 4 5 6 >>> a = (x for x in range (1 ,10 ))>>> aobject <genexpr> at 0x7faf6ee20a50 > >>> tuple (a) 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 )
Python3 迭代器与生成器 from【Python】从迭代器到生成器:小内存也能处理大数据_哔哩哔哩_bilibili 『教程』几分钟听懂迭代器_哔哩哔哩_bilibili
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。Python3 迭代器与生成器 | 菜鸟教程
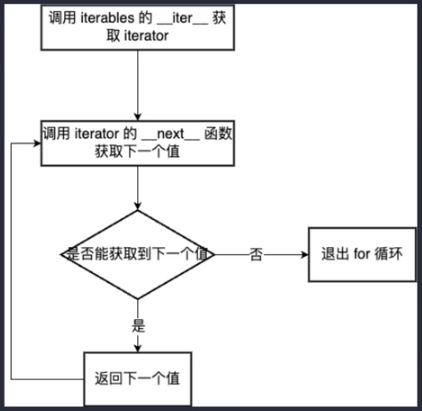
引入:for循环的原理
迭代器判断(迭代器协议):一个对象,只要它有__iter__方法,有__next__方法,就是一个迭代器。hasattr(obj,'method')
iter(可迭代对象)/__iter__(迭代器)–>返回一个迭代器next(迭代器)/__next__(迭代器)–>依次返回下一个值
实战:自定义一个迭代器,包含__init__,__iter__,__next__
惰性加载省内存:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import tracemallocclass LineIterator :def init_ (self, filepath ):self .file = open (filepath,def iter_ (self ):return self def next_ (self )self .file.readline()if line:return lineelse :self .file.close()raise StopIterationfor line in line_iter:print (f"Current memory usage:{current/1024 **2 } MB) print(f" Peak memory usage:{peak/1024 **2 } MB)
处理日志文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class LineIterator :def __init__ (self, filepath ):self .file = open (filepath, 'r' )def __iter__ (self ):return self def __next__ (self ):self .file.readline()while line:if line.split('|' )[2 ].strip() == 'Create' :return lineself .file.readline()self .file.close()raise StopIterationfor line in line_iter:print (line)
生成器则可以省略两个方法__iter__,__next__进行简化
特性:处理大型文件,实现惰性加载
Python with 关键字 with 语句的基本语法 1 2 with open ("" ,"" ) [as variable]:
expression 返回一个支持上下文管理协议的对象as variable 是可选的,用于将表达式结果赋值给变量代码块执行完毕后,自动调用清理方法
文件操作示例 最常见的 with 语句应用是文件操作:
1 2 3 4 with open('example.txt', 'r') as file:
这段代码等价于前面的 try-finally 实现,但更加简洁明了。
with 语句背后是 Python 的上下文管理协议,该协议要求对象实现两个方法:
__enter__():进入上下文时调用,返回值赋给 as 后的变量__exit__():退出上下文时调用,处理清理工作
Python3 函数 基本语法:
1 2 3 def 函数名(参数列表):
可更改(mutable)与不可更改(immutable)对象 对象有不同类型的区分,变量是没有类型的:
以上代码中,[1,2,3] 是 List 类型,”Runoob” 是 String 类型,而变量 a 是没有类型,它仅仅是一个对象的引用(一个指针),可以是指向 List 类型对象,也可以是指向 String 类型对象。
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
python 函数的参数传递:
不可变类型 :类似 C++ 的值传递,如整数、字符串、元组。如 fun(a),传递的只是 a 的值,没有影响 a 对象本身。如果在 fun(a) 内部修改 a 的值,则是新生成一个 a 的对象。可变类型 :类似 C++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后 fun 外部的 la 也会受影响
python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象。
参数 以下是调用函数时可使用的正式参数类型:
参数类型
说明
必需参数
没有默认参数时,不传参会报错
关键字参数
用参数名匹配参数值
默认参数
不传参会使用默认参数
不定长参数
可接收任意数量的参数(见下···)
不定长参数 希望一个函数能处理比当初声明时更多的参数:
1 2 3 def functionname([formal_args,] *var_args_tuple ):
加了星号 * 的参数会以元组(tuple)的形式导入,存放所有未命名的变量参数,举例:1 2 3 4 5 6 7 8 9 10 11 12 13 14 #!/usr/bin/python3
加了两个星号 ** 的参数会以字典的形式导入。1 2 3 def functionname([formal_args,] **var_args_dict ):
如果单独出现星号 *,则星号 * 后的参数必须用关键字传入,*不计入参数数。1 2 3 4 5 6 7 >>> def f(a,b,*,c):
强制位置参数(Python3.8+) 在以下的例子中,形参 a 和 b 必须使用指定位置参数,c 或 d 可以是位置形参或关键字形参,而 e 和 f 要求为关键字形参:
1 2 def f(a, b, /, c, d, *, e, f):
以下使用方法是正确的:
1 f(10, 20, 30, d=40, e=50, f=60)
Python3 匿名函数 语法:lambda (参数列表):(操作)
例如:
1 2 3 def f (a ):return (a+10 )print (f(5 ))
等价于
1 2 x = lambda a : a + 10
lambda 函数通常与内置函数如 map()、filter() 和 reduce() 一起使用。
这些内置函数都接受两个参数:函数和可迭代对象
Python 装饰器 无参数函数的装饰器 1 2 3 4 5 6 7 8 9 10 11 12 def my_decorator (func ): def wrapper (): print ("在原函数之前执行" ) print ("在原函数之后执行" ) return wrapper @my_decorator def say_hello (): print ("Hello!" )
输出:
1 2 3 在原函数之前执行
带参数函数的装饰器 1 2 3 4 5 6 7 8 9 10 11 12 def my_decorator (func ): def wrapper (*args, **kwargs ): print ("在原函数之前执行" ) print ("在原函数之后执行" ) return wrapper @my_decorator def greet (name ): print (f"Hello, {name} !" ) "Alice" )
输出:
1 2 3 在原函数之前执行
语法
处理参数类型
内部存储类型
*args位置参数
元组
**kwargs关键字参数(键值对)
字典
装饰器本身也可以接受参数,此时需要额外定义一个外层函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 def repeat (num_times ):def decorator (func ):def wrapper (*args, **kwargs ):for _ in range (num_times):return wrapperreturn decorator@repeat(3 def say_hello ():print ("Hello!" )
输出:
Python3 数据结构 列表
方法
描述
list.append(x)
把一个元素添加到列表的结尾
list.extend(L)
通过添加指定列表的所有元素来扩充列表
list.insert(i, x)
在指定位置插入一个元素。第一个参数是准备插入到其前面的那个元素的索引
list.remove(x)
删除列表中值为 x 的第一个元素(==指定值移除==)
list.pop([i])
从列表的==指定位置移除==元素,并将其返回。如果没有指定索引,a.pop()返回最后一个元素。元素随即从列表中被移除。
list.clear()
移除列表中的所有项
list.index(x)
返回列表中==第一个==值为 x 的元素的==索引==
list.count(x)
返回 x 在列表中==出现的次数==
list.sort()
对列表中的元素进行==排序==
list.reverse()
倒排列表中的元素
list.copy()
返回列表的浅复制,等于a[:]。(无参数)
可以将列表当做栈(LIFO)使用,也可以将列表当作队列(FIFO)使用(一般使用 collections.deque 实现队列)
字典 遍历字典技巧 在字典中遍历时,关键字和对应的值可以使用 items() 方法同时解读出来:
1 2 3 4 5 6 >>> knights = {'gallahad' : 'the pure' , 'robin' : 'the brave' } for k, v in knights.items(): ... print (k, v) ...
在序列中遍历时,索引位置和对应值可以使用 enumerate() 函数同时得到:
1 2 3 4 5 6 >>> for i, v in enumerate (['tic' , 'tac' , 'toe' ]): ... print (i, v) ... 0 tic 1 tac 2 toe
同时遍历两个或更多的序列,可以使用 zip() 组合:
1 2 3 4 5 6 7 8 >>> questions = ['name' , 'quest' , 'favorite color' ] 'lancelot' , 'the holy grail' , 'blue' ] for q, a in zip (questions, answers): ... print ('What is your {0}? It is {1}.' .format (q, a)) ... is your name? It is lancelot. is your quest? It is the holy grail. is your favorite color? It is blue.
补充 Python list 常用操作 | 菜鸟教程 一共有11个操作,都要学会
Python3 模块 查看官方文档Python 标准库 — Python 3.14.2 文档 PyPI · The Python Package Index ,使用pip命令安装
引入模块,如:
1 2 import statisticsprint (sttistics.median([69 ,124 ,-47 ,89 ,10 ]))
或from statistics import median(或*来匹配全部函数)
[!NOTE]
内置函数:直接用「函数名(参数)」调用,如 len("test") ;
模块函数:用「模块名.函数名(参数)」调用,需先导入模块,如 math.sin(0) 。
Python __name__ 与 __main__ __name__ 是一个内置变量,表示当前模块的名称。
假设我们有一个名为 example.py 的模块:
1 2 3 4 5 6 7 8 def greet (): print ("来自 example 模块的问候!" ) if __name__ == "__main__" : print ("该脚本正在直接运行。" ) else : print ("该脚本作为模块被导入。" )
如果你直接运行 example.py,输出将是:
1 2 该脚本正在直接运行。
在这种情况下,__name__ 的值是 “__main__“,所以 if __name__ == "__main__": 块中的代码会被执行。
如果你在另一个脚本中导入 example.py,例如:
1 2 3 4 5 import example
输出将是:
1 2 该脚本作为模块被导入。
在这种情况下,__name__ 的值是 “example”(模块名) ,所以 if __name__ == "__main__": 块中的代码不会被执行。
Python 爬虫(bs4模块) 爬虫的基本流程通常包括发送 HTTP 请求获取网页内容、解析网页并提取数据,然后存储数据。
解决中文乱码问题:response.encoding = 'utf-8' # 或者 'gbk',根据实际情况选择
获取标签内嵌的文本:get_text() 1 2 'p' ).get_text()
查找子标签和父标签:parent 和 children 属性 1 2 3 4 5
查找具有特定属性的特定标签:atters参数(字典) 1 all_titles = soup.findAll("span" , attrs={"class" : "title" })
如果是class属性或id属性,可以用class_=""和id=""
获取标签下的另一个属性: 1 2 3 4 5 6 'input' , id ='su' )'value' ] print (input_value)
[[CSS 选择器]] 1 2 3 4 5 'div.example' )'a[href="https:www.example.com"]' )
修改网页内容 1 2 3 'p' ) 'Updated content'
转换为字符串 你可以将解析的 [^1]BeautifulSoup 对象转换回 HTML 字符串:
Python requests 模块 每次调用 requests 请求之后,会返回一个 response 对象,该对象包含了具体的响应信息,如状态码、响应头、响应内容等:
1 2 3 4 print (response.status_code) print (response.headers) print (response.content) print (response.text)
如:
1 2 3 4 5 6 7 8 9 10 11 12 import requests'https://www.runoob.com/' )print (x.status_code)for key,value in x.headers.items():print (key,':' ,value)
方法
描述
get(url , params, args )
发送 GET 请求到指定 url
post(url , data, json, args )
发送 POST 请求到指定 url
request(method , url , args )
向指定的 url 发送指定的请求方法
request方法,如:
1 2 3 4 5 6 7 8 import requests'get' , 'https://www.runoob.com/' )print (x.status_code)
Python3 输入和输出 输入 举例:
1 user_height=float(input("请输入你的身高"))
输出格式美化 str.rjust() 的基本使用
1 2 3 4 5 6 7 8 9 10 >>> for x in range (1 , 6 ): ... print (repr (x).rjust(2 ), repr (x*x).rjust(3 ), end=' ' ) ... ... print (repr (x*x*x).rjust(4 )) ... 1 1 1 2 4 8 3 9 27 4 16 64 5 25 125
还有类似的方法, 如 ljust() 和 center()。
str.format() 的基本使用
1 2 >>> print ('站点列表 {0}, {1}, 和 {other}。' .format ('Google' , 'Runoob' , other='Taobao' ))
可选项:使用示例:{0:.3f}
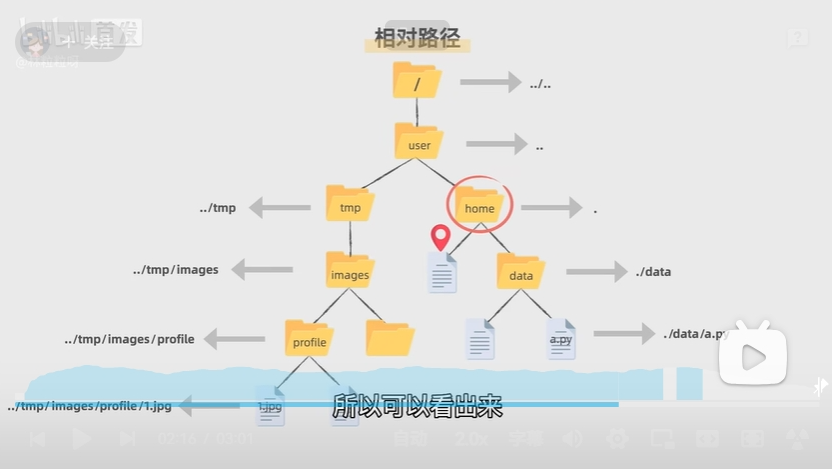
Python文件操作 文件路径 linux/
读写文件 %%003%%
如:
1 2 3 f=open("{路径名}","r/w")
或者用with方法:
1 2 with open(" ./data.txt") as f:
完整示例:%%模式有^2 rwa%%
1 2 3 4 5 with open("./poem.txt","w+") as f: # w+支持读,写,创建新文件
Python3 OS 文件/目录方法 通过 os 模块,你可以执行文件操作、目录操作、环境变量管理、进程管理等任务。
获取当前工作目录
改变当前工作目录
列出目录内容
创建目录
删除目录
删除文件
重命名文件或目录
获取环境变量
执行系统命令os.system(command)
Python3 错误和异常 try...except...else...finally...
Python 面向对象
类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。实例化: 创建一个类的实例,类的具体对象。对象: 通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
简述: 类 是模板,对象 是实例,方法 是放在类里面的函数属性 ,且可以区分来自不同对象的属性,属性可以被方法直接获取(不用作为参数)
基本语法 %%001%%
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Student :def __init__ (self,name,id ,yw,sx,yy ):self .name=nameself .id =id self .yw=ywself .sx=sxself .yy=yydef caculate_all (self ):print (f"总成绩为:{self.yw+self.sx+self.yy} " )"张三" ,202510 ,110 ,120 ,130 )print (zhangsan.id )
继承(父子类) %%002%%
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class yuangong :def __init__ (self,name,id ):self .name=nameself .id =id self .work_city="zhongshan" def print_info (self ):print (f"员工姓名:{self.name} ,id:{self.id } ,city:{self.work_city} " )class quanzhi (yuangong ):def __init__ (self, name, id , yx ):super ().__init__(name, id ) self .yx=yxdef salary_count (self ):return self .yxclass jianzhi (yuangong ):def __init__ (self, name, id ,rx,days ):super ().__init__(name, id )self .rx=rxself .days=daysdef salary_count (self ):return self .rx*self .days"张三" ,202510 ,6000 ) "李四" ,202511 ,180 ,15 )print (zhangsan.salary_count())print (lisi.salary_count())print (zhangsan.id )
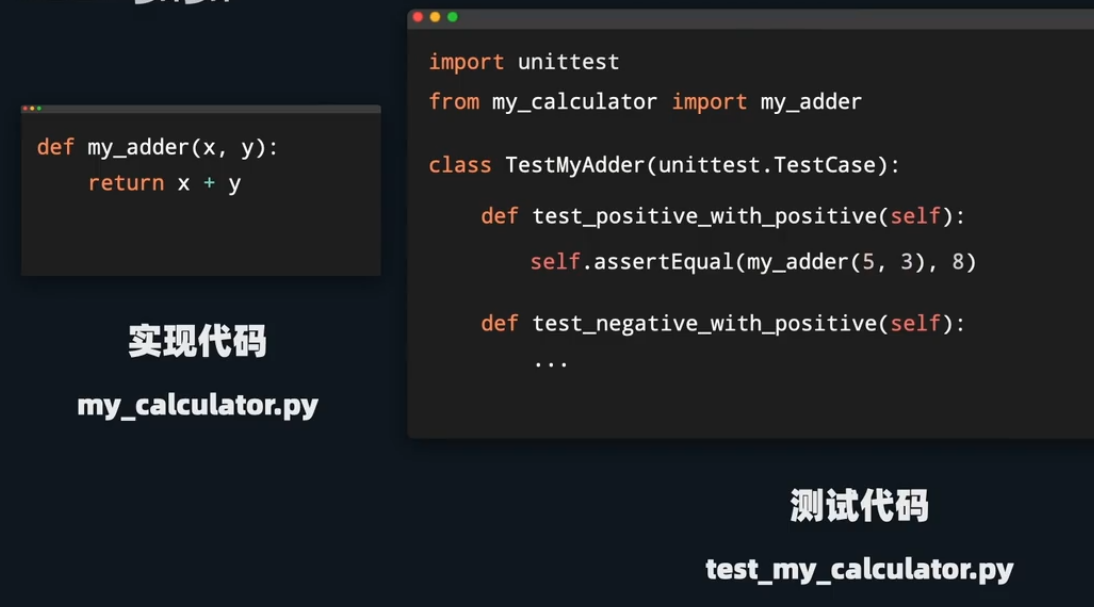
python测试模块:unittest %%004%%
再在终端运行python -m unittest
测试代码:(”test_”开头的文件名)
1 2 3 4 5 6 7 8 9 10 11 import unittest:from {同目录下被测试文件名} import {被测试文件类名}class {自定义类名} (unittest.TestCase):def setUp (self ):self .{自定义属性}={被测试文件类名}({被传入的数据}) def {"test_" 开头的方法名} (self ):self .{assertEqual等}(参数1 ,参数2 ) def ...
Python 虚拟环境的创建(venv) 完整示例 假设开发一个 Django 项目:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 source .venv/bin/activate cd my_site
目录结构 创建.venv后的目录结构
1 2 3 4 5 6 7 8 9 10 .venv/
使用虚拟环境 %%记得激活与退出%%
安装包 在激活的环境中,使用 pip 安装的包只会影响当前环境:
1 pip install package_name
例如:
1 2 3 4 5
查看已安装的包 1 2 3 4 5 (.venv) pip list
导出依赖 1 (.venv) pip freeze > requirements.txt
requirements.txt 文件内容示例:
1 2 3 Django==3.2.12
从文件安装依赖 1 (.venv) pip install -r requirements.txt
Python 类型注解(Type Hints) %%也可以使用typing 模块%%
基础语法 变量注解 从 Python 3.6 开始,你可以直接为变量添加类型注解:
1 2 3 4 5 6 7 8 9 10 11 "Alice" 30 False 95 , 88 , 91 ] str = "Alice" int = 30 bool = False list = [95 , 88 , 91 ]
说明: name: str 读作”变量 name 的类型是 str”。
函数注解 在函数参数后加 : 类型。
1 2 3 4 5 6 7 8 9 def greet (first_name, last_name ): " " + last_name return "Hello, " + full_name def greet (first_name: str , last_name: str ) -> str : " " + last_name return "Hello, " + full_name
解读这个函数 :
first_name: str:参数 first_name 应该是字符串。last_name: str:参数 last_name 应该是字符串。-> str:这个函数执行后会返回一个字符串。
现在,任何人调用这个函数时,都能清晰地知道需要传递什么,以及会得到什么。
函数注解是类型注解最常见的应用场景:
1 2 3 4 5 6 7 def add_numbers (a: int , b: int ) -> int : """将两个整数相加并返回结果""" return a + b 5 , 3 )
参数默认值 你可以同时使用类型注解和默认值:
1 2 3 4 5 6 def say_hello (name: str , times: int = 1 ) -> str : """向某人问好指定次数""" return " " .join([f"Hello, {name} !" ] * times) print (say_hello("Bob" )) print (say_hello("Alice" , 3 ))
Python3 标准库概览 菜鸟 :Python3 标准库概览 | 菜鸟教程 官方 :Python 标准库 — Python 3.14.2 文档 第三方库 :PyPI · The Python Package Index
[^1]: 使用 BeautifulSoup 解析 HTML 后会生成 BeautifulSoup 对象,该对象以嵌套树形结构表示整个 HTML 文档,便于后续的导航、搜索和数据提取
|---|---|---|---|---|---|---|
|读|+|+||+||+|
|写||+|+|+|+|+|
|创建|||+|+|+|+|
|覆盖|||+|+|||
|指针在开始|+|+|+|+|||
|指针在结尾|||||+|+|